
The UNL Programme aimed to create a multilingual infrastructure composed of language resources and processing tools that allowed individuals to generate and access information in their own languages. Its broader mission was to support intercultural exchange, dialogue among civilizations, peace, and development worldwide. The Programme was conducted first by the Institute of Advanced Studies of the United Nations University in Tokyo (1996–2001) and later by the UNDL Foundation in Geneva (2001–2015).
The Universal Networking Language Programme represented one of the most ambitious initiatives ever undertaken to bridge the linguistic divides that have long separated humanity. Born within the United Nations and conceived at the Institute of Advanced Studies of the United Nations University, the Programme's mission was to enable all peoples to generate and access information and knowledge in their native languages and cultures, breaking down the barriers that isolated countless individuals from the global community.
The Programme pursued this mission with two interconnected goals. The immediate objective was to construct a multilingual infrastructure capable of dissolving the linguistic barriers that excluded so many from participating in the emerging digital global society—barriers that existed simply because dominant languages monopolized the expression of culture and knowledge. The broader, more profound aspiration was to facilitate genuine interchange of cultural values among all the world's peoples, thereby contributing to dialogue among civilizations, to lasting peace, and to the equitable development of all nations.
The UNL Programme was initiated in 1996 as a pioneering effort to create a multilingual information infrastructure that would enable people worldwide to access and share knowledge in their native languages. The Programme was conducted from 1996 to 2001 under the auspices of the Institute of Advanced Studies at the United Nations University (UNU) in Tokyo, Japan, and from 2001 to 2015 by the autonomous UNDL Foundation based in Geneva, Switzerland.
The UNL Programme began in 1996 as an initiative of the Institute of Advanced Studies (IAS) at the United Nations University (UNU) in Tokyo, Japan. From its inception, it engaged a consortium of university departments from all regions of the world in its development, the so called "Language Centres". A global-scale network of research and development teams, involving approximately 200 specialists in computer science and linguistics, worked to create the linguistic resources and develop the web structure of the UNL System, with the UNL Centre, in Tokyo, providing technological support and coordinating implementation across this distributed network.
The following institutions served as UNL Language Centres, each responsible for developing linguistic resources and tools for their respective languages:
At the turn of the millenium, UNL dictionaries for fifteen languages had been compiled, containing between 50 K and 200 K words depending on the language. Each Language Centre developed the grammar rules required to interface between their language and the UNL. The structure of the UNL Knowledge Base was defined, and the inventory of human knowledge grew continuously with new entries.
The Programme's development was marked by numerous international and regional symposia, workshops, and meetings. Following the initial launch at the United Nations University in Tokyo in November 1996, international symposia were organized at UNESCO (Paris, 1997), the United Nations (New York, 1998) and the European Community (Brussels, 1999). Technical workshops took place in Beijing (1997, 1999), Curitiba (1997), Madrid (1998), Phuket (1998), and Perugia (1999), bringing together researchers and developers from around the world.
Originally restricted to the Language Centres, the UNL Programme was opened to a broader community, the so called UNL Society, in 1999, with the publication of A Gift for a Millennium, a brochure inviting researchers and developers from around the world to join the initiative. This marked a significant expansion of the Programme's reach, allowing individual researchers and groups to contribute to the development of the UNL System.
The First Open Conference on UNL took place in November 2001 in Suzhou, China. By the early 2000s, the UNL Society had grown to 240 members from 30 countries, all with access to the tools necessary for developing and advancing the UNL System. This community exemplified the Programme’s commitment to open, collaborative development and proved essential to its continuity during challenging times.
In January 2001, the United Nations University established an autonomous organization, the UNDL Foundation, to assume responsibility for the development and management of the UNL Programme. Structured as a non-profit international organization with headquarters in Geneva, Switzerland, the Foundation maintained an independent identity from the United Nations University while preserving special links with the UN system. It inherited from the UNU/IAS the mandate of implementing the UNL Programme and fulfilling its ambitious mission.
The UNDL Foundation built upon the achievements of the earlier phase, leveraging the linguistic resources and technological infrastructure developed during the initial years of the Programme. It sought to enhance the UNL System's capabilities and expand its user base, promoting the adoption of UNL technologies in various domains.
One of the Programme's most significant accomplishments was the recognition by the Patent Cooperation Treaty (PCT) of the innovative character and industrial applicability of the UNL, achieved in May 2002 through the World Intellectual Property Organization (WIPO). This patent acquisition represented a completely novel achievement within the United Nations system and underscored both the technological innovation embodied in the UNL and the commitment to maintaining it as a resource for all humanity.
During these years, the UNDL Foundation continued to organize international symposia and workshops, fostering collaboration and knowledge exchange among researchers and developers. Notable events included meetings held at the United Nations Office in Geneva (2001) and workshops in Petra (2001), Goa (2002), Alexandria (2003, 2004), Mumbai (2003), Yerevan (2004), Florianópolis (2005) and Geneva (2006).
Despite its technical achievements and international support, the Programme faced significant challenges in securing sustainable funding and achieving widespread adoption. By the mid-2000s, financial constraints forced a drastic reduction in activities, and the Language Centres could no longer be funded at their previous levels. This period marked a difficult transition for the Programme, as the ambitious vision of a comprehensive global network confronted the practical realities of long-term institutional support.
However, the UNDL Foundation demonstrated remarkable resilience during this challenging period. Rather than abandoning its mission entirely, it adapted by redirecting resources toward strategic projects. The Foundation maintained several important initiatives that showcased the practical applications of UNL technology, such as the UNLization of the EOLSS (Encyclopedia of Life Support Systems), which illustrated UNL’s potential to democratize access to scientific and educational content.
These projects, though more limited in scope than the original ambitious network of Language Centres, kept alive the core vision of the Programme and demonstrated practical pathways for applying UNL technology to real-world challenges in multilingual knowledge management and communication.
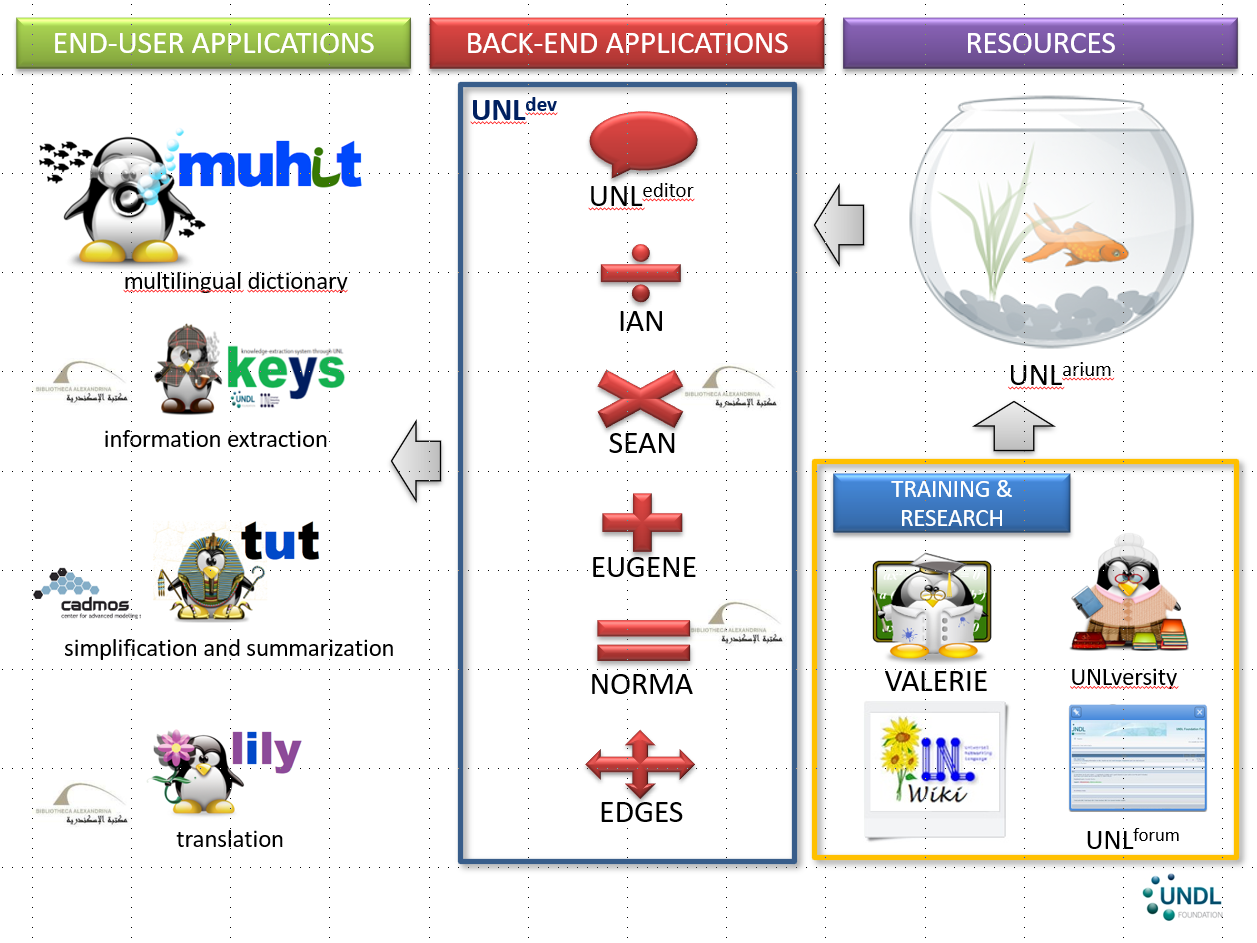
From 2009 to 2015, the UNDL Foundation entered a period of consolidation and expansion, marked by renewed partnerships, technological renewal, and global outreach. The Foundation regained funding, specially from the Arab Fund for Economic and Social Development, and established a strategic and profitable partnership with the Library of Alexandria in Egypt. This collaboration provided the resources and institutional support needed to redevelop the UNL System from the ground up in the UNL+3 project.
During this phase, the old tools, EnCo and DeCo, which had been developed in the late 1990s by the UNL Centre, were replaced by a new generation of high-level, linguist-friendly engines—IAN, SEAN, and EUGENE. These were fully integrated into a web-based development environment, UNL{dev}, providing a seamless platform for creating and managing UNL resources.
To support collaborative development, the UNDL Foundation launched the UNLarium, a crowdsourcing environment for language resources development. Accredited users from around the world could create, edit, and revise entries across different domains and projects, significantly extending the reach and productivity of the UNL Programme.
The Foundation also invested in training and research initiatives. It developed VALERIE, the Virtual Learning Environment for UNL, and established the UNLversity, which organized the UNL Panel and 10 UNL Schools, alongside the 4 UNL Olympiads, fostering education and capacity building in computational linguistics and UNL technologies.
Documentation and knowledge dissemination were enhanced through the UNLwiki, a collaborative encyclopedia detailing the UNL formalism, rules, and best practices. All tools and resources were made accessible through UNLweb, a central web portal for the UNL community, including the UNL Forum and the UNL Community, which facilitated interaction and collaboration among researchers and developers worldwide.
With a strengthened infrastructure, the UNDL Foundation was able to develop end-user applications, including Muhit (a multilingual dictionary), Lily (a machine translation system), Keys (an information retrieval system), and TUT (a text processing system). Over the following six years, the Foundation hosted numerous events and projects in collaboration with institutions such as the Cadmos Consortium and the University of Geneva (LACE project), the Library of Alexandria (LIS and UNL Core), and the University of Patras (Liddel & Scott for Ancient Greek, Lewis & Short for Latin), in addition to in-house initiatives such as the UNLization of Le Petit Prince and several other projects (BRUNO, CORNELIA, FRIDA, MIR, UGO).
By December 2015, the UNL Programme had grown to include more than 2,000 users, covering over 100 languages and providing more than 2M entries, including both dictionary and grammar resources. VALERIE - the Virtual Learning Environment for UNL - had issued more than 1,500 certificates.
However, by the end of 2015, the Foundation once again faced funding difficulties. The paradigm shift from symbolic, rule-based approaches to statistical and data-driven methods in natural language processing diverted available funds, forcing the closure of most projects. Ultimately, the UNDL Foundation could no longer sustain its staff and had to cease operations, entering a period of hibernation while awaiting renewed interest in dictionary- and rule-based language resources. The Foundation was formally dissolved in 2024.
Despite these challenges, the UNL Programme's legacy endures. It laid the groundwork for future research in multilingual information processing and demonstrated the potential of collaborative, open-source approaches to language technology development. The Programme's vision of a world where everyone can access and share knowledge in their native languages remains a guiding principle for ongoing efforts in this field.
The Universal Networking Language (UNL) is an artificial language created to represent and process information across language barriers. It functions as a computational formalism for knowledge representation rather than a human communication tool. It is designed to capture and convey the semantic content of natural language texts in a machine-tractable, unambiguous format.
UNL serves as an infrastructure for handling knowledge independently of natural languages and computing platforms. It acts as a semantic markup language that represents the essential content and meaning of texts rather than their surface form, enabling information to be represented, processed and regenerated in multiple human languages.
UNL represents information as a hypergraph (semantic network) composed of three discrete semantic entities: Universal Words, Universal Relations and Universal Attributes.
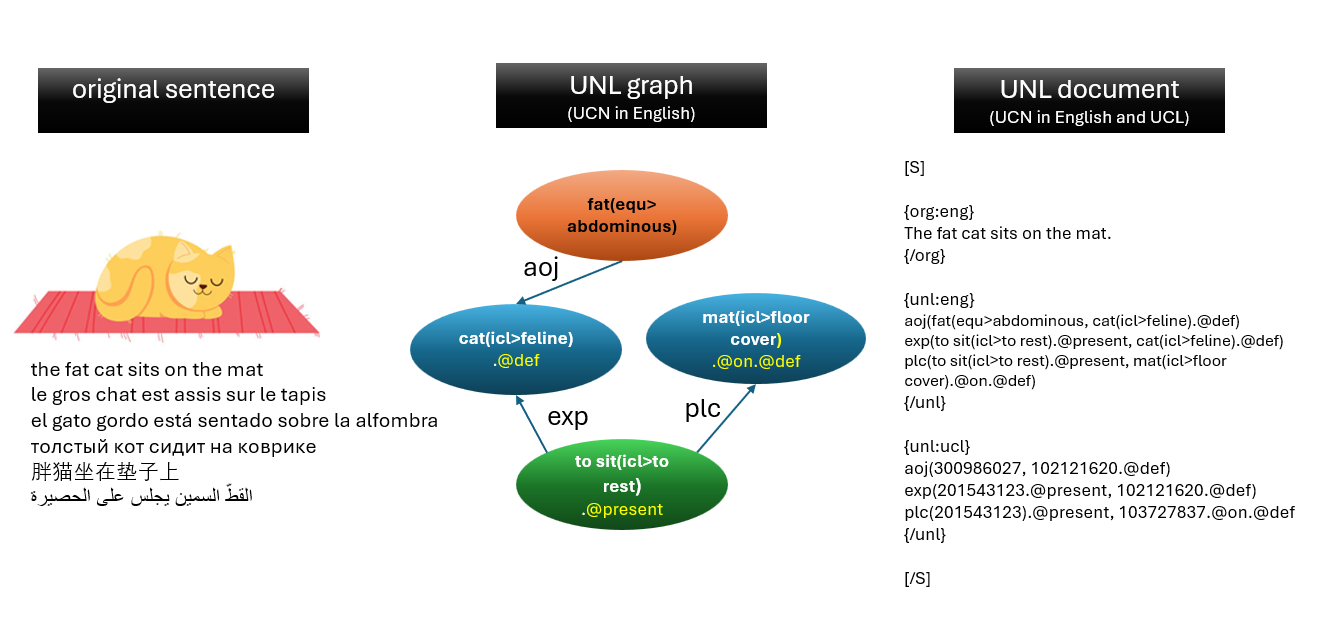
Universal Words represent concepts and serve as nodes or hypernodes in the network. They are standardized, universally-accessible semantic units that reference concepts rather than language-specific words.
Example: "cat(icl>feline)", "mat(icl>floor cover)", "to sit(icl>to rest)", and "fat(equ>abdominous)" are uniform concept names (UCN) for Universal Words, which may be expressed in different languages (here, in English) in order to keep the UNL code readable. In the UNL system, however, they are internally represented by the corresponding uniform concept locators (UCL) in the UNL Knowledge Base (a 9-digit code).
Universal Relations are labeled semantic links connecting nodes, including:
Example: "aoj" (attribute of object) linking "fat" to "cat", "exp" (experiencer) linking "sit" to "cat", and "plc" (physical place) linking "sit" to "mat".
Universal Attributes delimit and specify the use of nodes, encoding:
Example: "@def" specifies that the cat and the mat are the specific instances being referred to; "@present" specifies that the cat is sitting on the mat at the current time; and "@on" specifies that it is sitting on top of the mat.
UNL is fundamentally a knowledge representation system. It represents "what was meant" rather than "what was said", providing interpretations rather than literal translations. The UNL version of a document preserves semantic content while potentially differing from the original in lexical and syntactic choices.
Unlike auxiliary languages such as Esperanto or Interlingua, UNL is specifically designed for computers, not humans. It enables machines to:
UNL is designed to be independent of any particular natural language. It uses a standard set of semantic entities that are universally accessible and not tied to the grammar or vocabulary of any specific language. This neutrality is essential for its role as a potential language infrastructure for the United Nations, ensuring no bias toward any member state's language.
UNL representations are semantically complete and saturated, explicitly codifying all information without relying on implicit knowledge. This ensures that:
UNL is governed by several key principles that ensure its effectiveness as a knowledge representation system:
As a formal system, UNL eliminates all ambiguity. The sentence "The girls saw the boy with the telescope" must clearly indicate whether "saw" is past tense of "see" versus "saw" (the tool), and whether the telescope belongs to the boy or was used for seeing.
UNL eliminates redundant expressions. "Free gift", "round circle", and "murder to death" are represented simply as "gift", "circle", and "murder". Semantically equivalent sentences like "Peter killed John" and "John was killed by Peter" receive identical UNL representations.
UNL is fully literal and compositional—semantic values derive entirely from explicitly defined components. Figures of speech (metaphors, metonymy) must be represented by their intended meanings. "John devoured thousands of books" becomes "John read many books eagerly."
UNL describes speech acts rather than performing them. A request like "Can you pass me the salt?" is represented as "you pass the salt to me" with attributes indicating it was a polite request (@polite, @request).
UNL representations are fully explicit, avoiding ellipses and pro-forms except for exophoric references. "The monkey took the banana and ate it" is represented with explicit repeated references: "[The monkey]ᵢ took [the banana]ⱼ and [the monkey]ᵢ ate [the banana]ⱼ."
During its operation, UNL was applied in:
UNL enabled rephrasing, summarizing, or simplifying texts even in the same language, demonstrating its versatility beyond translation.
The UNL System comprised three essential components that worked in concert: linguistic resources and the software technology to manage them, and the applications that could be generated from this foundation.
The UNL System's linguistic resources included:
The software technology underpinning the UNL System included:
The UNL System enabled the development of various applications, including:
The UNL Programme represented a remarkable vision: that technology could serve not merely to translate between languages, but to create a genuine space for intercultural dialogue and knowledge sharing. It embodied the conviction that linguistic diversity, far from being a barrier to overcome, was a heritage to be preserved and celebrated—and that digital technology could be harnessed to honor that diversity while enabling universal communication.
Though the active phase of the Programme has concluded, its legacy endures in the relationships it fostered, the technical innovations it produced, the research it inspired, and most importantly, in the vision it articulated: a world where every language and culture has equal standing in the digital realm, where knowledge flows freely across linguistic boundaries, and where technology serves the cause of mutual understanding among all peoples. The UNL Archive exists to preserve this legacy and to keep alive the memory of what was attempted, what was achieved, and what remains possible when humanity commits itself to building bridges across the divides that separate us.