
The language resources — including dictionaries, ontologies, knowledge bases, example bases, grammars, and corpora — developed within the UNL framework were managed and produced using the UNLarium, a crowdsourcing development environment created by the UNDL Foundation. Although originally conceived as part of the UNL formalism, the platform was designed for integration with a wide range of natural language processing (NLP) systems, extending beyond strictly UNL-based applications. It also served as a research environment for testing linguistic hypotheses and proposing constants for the description and prediction of natural language phenomena. One of its primary goals was to advance the development of a language-independent metalanguage for multilingual processing.

The UNLarium was a web-based database management system that enabled accredited users to create, edit, and export entries and rules in accordance with the UNDL Foundation's standards for language engineering. It provided a collaborative environment for linguists and language professionals to contribute to the development of linguistic resources for natural language processing tasks, particularly within the UNL framework. The platform facilitated the creation of multilingual dictionaries, grammar rules, and aligned corpora, supporting both natural language analysis (NL>UNL) and generation (UNL>NL).
|
The UNLarium houses a comprehensive collection of linguistic resources developed under the UNL framework. The platform is organized into distinct compartments — lexical databases, rule bases, and document bases — all designed to be bidirectional for natural language analysis and generation. Standardized tags and formalism ensure consistency, enabling aligned multilingual databases and promoting dialogue between different linguistic traditions and models of language description. The main components include: Lexical Resources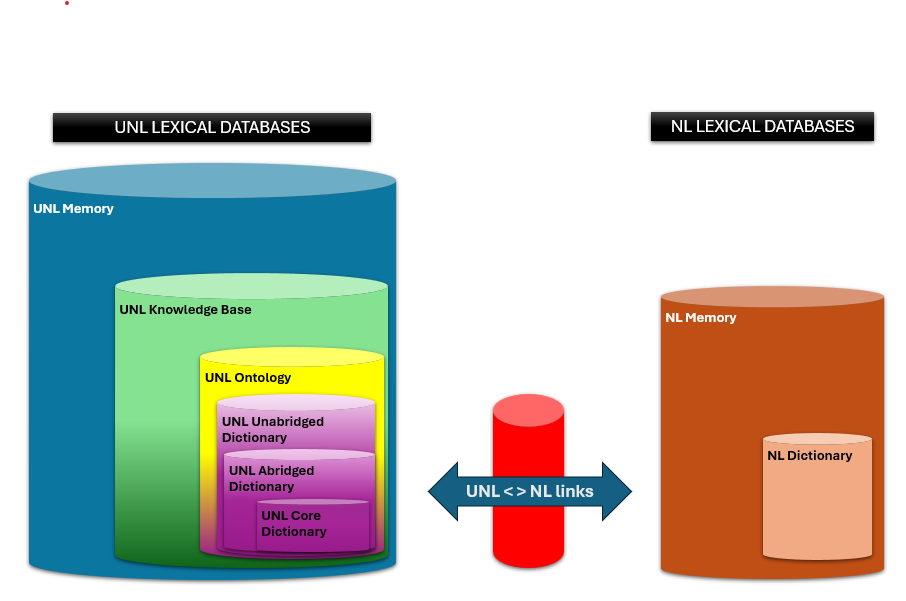
Grammar Resources
Corpora
|
|
The resources in the UNLarium were created by a global community of over 2,000 linguists and language professionals, contributing to the development and validation of the UNL formalism across more than 100 languages. The platform was designed to be as linguist-friendly as possible, targeting language specialists rather than computer experts. It did not require prior expertise in UNL or computational linguistics, though users were expected to have solid linguistic knowledge and an excellent command of their working language. Participation in the UNLarium also required accreditation through VALERIE, the Virtual Learning Environment for UNL. Accredited users could contribute dictionary entries and grammar rules. They created assignments to reserve entries and address specific linguistic tasks, such as developing dictionaries or grammars for particular languages or projects, and could work on them at their own pace. Unfinished assignments were automatically returned after 30 days. Contributors could act as volunteers, freelancers, institutional partners, or employees of the UNDL Foundation. Remuneration, when applicable, was determined by user level and productivity (measured in UNLdots). Paid work was limited to specific projects and languages, depending on available funding. Editorial oversight was maintained through a double-checking mechanism involving editors and revisers. Each entry or rule created was revised twice to ensure quality, and contributors could be promoted or demoted based on their performance. |
|
The UNLarium employed a structured workflow to manage contributions and ensure quality control. The process involved several key steps:
|
|
The lingware development process within the UNLarium was guided by the Framework of Reference for UNL (FoR-UNL), a set of guidelines and standards for assessing and classifying the linguistic resources developed within the UNL programme. Inspired by the CEFR model, FoR-UNL established reference levels and measurable descriptors to evaluate the availability and quality of dictionaries, grammars and corpora for each language. Languages were classified in six progressive levels, according to the number of entries (base forms in the NL dictionary) and to the grammatical structures covered:
This classification allowed for a systematic evaluation of linguistic resources, facilitating the identification of gaps and areas for improvement. |
|
Within the system, contributors were assigned levels according to their accumulated UNLdots — a unit designed to measure effort and task complexity. These levels reflected both productivity and expertise, ranging from A0 (beginner) to C2 (expert).
The seven user levels were:
|
Participation was free and open to individuals and institutions worldwide, and user permissions were determined by level, expertise, and accreditation:
|
 The data stored in the UNLarium are available under an Attribution Share Alike (CC-BY-SA) Creative Commons license. These resources are preserved as is, for reference and reuse, provided proper credit is given and derivative works are released under the same or a compatible license.
The data stored in the UNLarium are available under an Attribution Share Alike (CC-BY-SA) Creative Commons license. These resources are preserved as is, for reference and reuse, provided proper credit is given and derivative works are released under the same or a compatible license.
|
| Documentation and community discussions were originally hosted in the UNLwiki and the UNLforum, respectively. These materials are preserved here for archival purposes. No further updates or support are currently provided |
|
The UNLarium is a database management system. All data is stored in tables in a MySQL database. To download and use the data, you have to export them using the built-in export functionality. The data is always exported in plain text format, using UTF-8 encoding. You may export data from the following modules: DictionariesEnter the dictionary module in the UNLarium, select the desired language, and use the export function to download the entries. For each language there are three types of dictionaries available for export:
You may choose to export the entire dictionary or specific subsets based on criteria such as part of speech, semantic category or project. The dictionary is exported according to the Dictionary Specs, i.e., as a list of entries in the format: [natural language entry] {ID} “UW” (ATTRIBUTE=VALUE , ... ) < LANGUAGE CODE , FREQUENCY , PRIORITY >; COMMENTS
You will find an example of the English>UNL dictionary for the corpus "Le Petit Prince" here;
GrammarsEnter the grammar module in the UNLarium, select the desired language, and use the export function to download the grammar rules. For each language there are three types of grammars:
You may choose to export the entire grammar or specific subsets based on criteria such as rule type or project. The grammar is exported according to the Grammar Specs, i.e., as a list of rules in one of the following formats: α:=β; for transformation (rewrite) rules or α=P; for disambiguation rules.You will find an example of the English>UNL transformation grammar for the corpus UC-A1 here; CorporaThe exported data can be imported into UNLdev or UNLCore tools (IAN, SEAN, EUGENE, and NORMA) to perform natural language analysis and generation using the UNL framework. Alternatively, you may parse the text files in accordance with the relevant specifications (Dictionary Specs, Grammar Specs, and UNL Specs) and integrate them into your own natural language processing system or application. |